자세한 코드는 아래 링크에서 2_11번가_리뷰_긍부정_분류(긍부정_영향_미치는_단어_탐색).ipynb를 확인해주세요!
깃허브: https://github.com/ChangdaeVictorLee/NLP_11st_review
2번 리뷰 긍부정 모델 포스팅에서 KoBERT를 활용해 긍정 부정을 분류해 냈습니다. 작년 여름 부트캠프 당시에는 어떤 단어가 긍/부정에 영향을 미쳤는지 구현하고자 했으나 시간부족으로 하지 못했습니다.
그래서 이번에 활동을 정리하며 긍정과 부정에 영향을 미친 단어에 대해서 알아보고자 합니다.
1) KoBERT Weights 활용 2) 감정사전
2가지 방법을 통해 알아보았습니다.
KoBERT 파인튜닝


BERTClassifier을 정의한 후 이전에 state dict로 저장했던 모델을 불러옵니다.
모델은 다음과 같이 이루어져 있습니다.


주어진 리뷰 문장이 입력되면 이에 대해 KoBERT vocab에서 원핫 인코딩을 진행합니다. vocab은 8002개의 단어로 구성되어 있고 주어진 문장에 대해 vocab의 단어가 존재한다면 1 아니면 0으로 바꾸는 과정입니다. 그러나 이럴 경우 0으로 이루어진 공간이 많이 생기기에 임베딩이란 과정을 통해서 이 문제를 해결합니다.
8002개로 원핫 인코딩 된 문장을 768로 줄여주는 8002*768 행렬로 곱해주는 방식입니다. 그럼 기존의 8002개 열에서 768개의 열로 줄어들게 됩니다.
이렇게 임베딩 된 데이터를 BERT에 통과시킨 후 나온 값을 Fully Connected Layer(Linear Layer)에 통과시킵니다. 이를 통해 긍정, 부정을 분류할 수 있게 됩니다.
긍정/부정 단어에 대한 단서
최종 Fully connected Layer은 긍정, 부정과 바로 연결되어 있는 층입니다. 이 층은 768*2 행렬로 가중치를 포함하고 있습니다. 아래의 weights.shape이 이를 보여줍니다.
또한 위에서 임베딩에서는 단어에 대한 정보를 가지고 있습니다. 단어에 대한 정보를 압축해 8002*768행렬(아래 word_embeddings.shape 참고)에 포함하고 있다고 이해할 수 있습니다.
즉, 이 두 행렬의 곱을 통해 긍정/부정 단어에 대한 단서를 얻을 수 있습니다.


weights를 transpose해 두 행렬의 행렬곱을 구하면 위와 같은 행렬을 얻을 수 있습니다. 이는 8002개 단어에 대한 0(부정), 1(긍정)에 영향을 미치는 가중치로 이해할 수 있습니다.
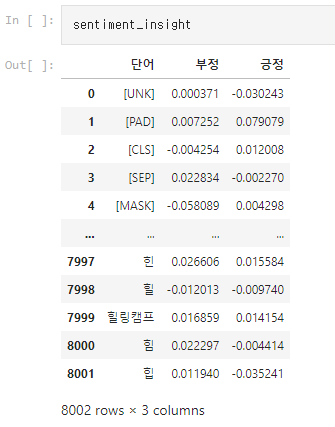

이를 정리하면 위와 같은 dataframe을 얻을 수 있습니다. 각 단어에 대한 부정, 긍정에 영향을 미치는 수치를 확인할 수 있습니다.
이 중 일부를 확인해보면 위와 같이 '나쁜'이라는 단어는 부정에 +, 긍정에 - 영향을 미치는 것을 확인할 수 있습니다.
다만, 이 점수를 통해 단어가 어떤 역할을 하는지 대략적인 추론만 가능하다는 단점을 보입니다.
다른 방법
지금까지 BERT 모델의 가중치를 기반으로 단어의 감정에 대한 인사이트를 얻을 수 있는 방법에 대해 설명했습니다. 이외에도 다른 방법에 대해 찾아보았습니다.
1. Attention weights
BERT 모델이 문장을 처리할 때 Attention Weights를 검사하는 방식입니다. 모델이 어떤 단어에 주목했는지를 통해 단어가 긍정 부정과 어떤 연관을 가지는지 이해할 수 있습니다.
2. 시각화
모델이 어떻게 활성화되는지에 대해 시각화를 하는 방법이 있습니다. TensorBoard등의 툴을 활용해 시각화를 할 수 있습니다.
3. 임베딩 추출
단어나 구문의 임베딩을 추출한 다음 PCA 또는 t-SNE와 같은 차원 축소 기법을 사용하여 2차원 공간에서 시각화할 수 있습니다. 이 공간에서 유사한 단어의 군집을 사용하면 유사한 단어에 대한 모델의 이해를 알 수 있습니다.
감정사전 이용
한국어 문장 감정사전을 아래 링크에서 가져와서 긍/부정 예측을 진행해보았습니다.



감정사전은 위와 같이 단어에 대한 점수를 나타내고 있습니다. 이를 활용해 리뷰에서 점수를 계산해보았습니다.(2000개 리뷰만 진행)
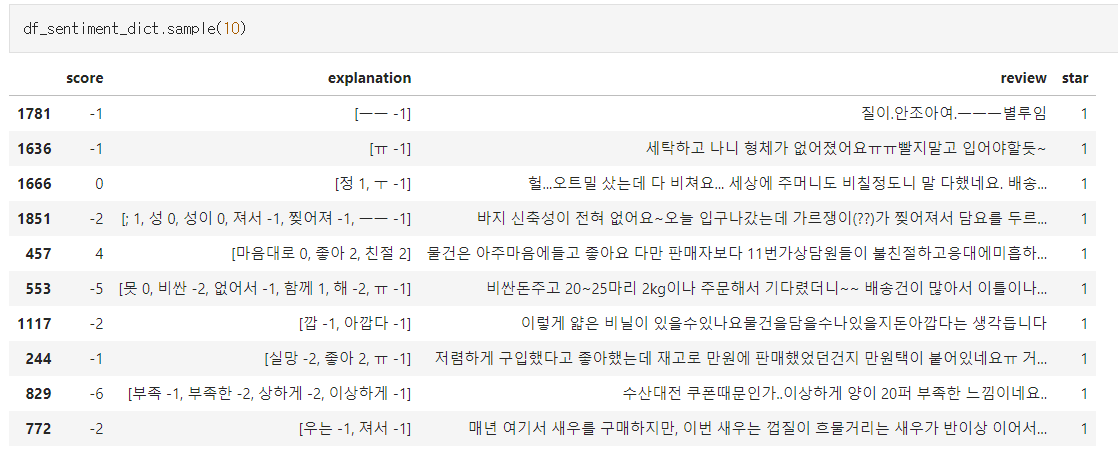
이후 10개의 리뷰를 뽑아 확인해보았습니다. 1점리뷰에 대해 음의 점수를 주었기에 나쁘지 않게 분류해 내는 모습을 볼 수 있습니다. 또한 explanation에서 부정에 영향을 준 단어를 볼 수 있다는 장점이 있습니다.
그러나, 감정사전에서 '해'라는 단어가 -2점을 주고 있는데 주문해서의 '해'가 인식되어 -2점을 준다는 점에서 감정사전 자체의 문제점을 확인할 수 있습니다. 동음이의어인 harm의 의미를 지닌 해와 sun 혹은 하다의 변형 을 구분 못하기에 정확한 점수를 주기에는 문제점이 있다는 것을 확인했습니다.
딥러닝을 활용하면 정확도는 많이 올라가지만 이를 설명할 수 있게 만드는 게 어려워진다는 점을 확인할 수 있었습니다.
'SKT FlyAI(인공지능 교육)' 카테고리의 다른 글
| 리뷰 긍부정 모델 - AI를 활용한 유저친화적 CLEAN 리뷰 시스템 구현 (0) | 2023.01.25 |
|---|---|
| 리뷰 크롤링 - AI를 활용한 유저친화적 CLEAN 리뷰 시스템 구현 (0) | 2023.01.24 |
| (개요) AI를 활용한 유저친화적 CLEAN 리뷰 시스템 구현 (1) | 2023.01.24 |